


A New Newsletter - #0
Here's to something new

What Is This Newsletter?
So let's get this out of the way, it being the first newsletter and all– what is this newsletter going to be about?
Honestly, I really don't know yet!
My main motivation has been along the lines of: "Let's put yourself out there; maybe someone finds a thing you say interesting."
And that's what I want to do– put out things that seem a bit interesting to me and maybe if I'm lucky, it'll be interesting to someone else! Or even more than one someone else! I'm not looking to 'optimize' sharing or 'building an audience'. I really just want to share in the hopes that maybe a few readers get something out of what I have to say.
So here are the kind of things that come to mind right now for this newsletter:
My interests and experience working in developing ML/AI
Education and outreach, especially for those not coming from a 'technical' background
My want to dig more into linguistics– which matches well with my work in natural language processing (NLP)
A place to share my current thoughts & things I'm just trying out
One way to summarize a bit of my overall philosophy on viewing the world is that nothing is 100% certain, but we can weigh out the possibilities.
The idea "You can't win the lottery without buying a ticket" resonates with me. And it's not because I'm thinking about winning the metaphorical 'lottery' (or the actual lottery– I've never bought a ticket). It's more that doing something out of the ordinary from your typical routine or set of habits can lead to something pleasantly unordinary, if not extraordinary.
This is me buying a lottery ticket in the hopes of sharing something you might find interesting.
Taking a chance every now and again can lead to something special.
Consider hopping around in this newsletter; don’t feel obligated to read top to bottom. Check what peaks your interest & skip what doesn’t. If you find something, feel free to comment and start a discussion on Substack or wherever. (But tag me in since I like a good discussion thread 😄). Consider even picking at something that’s different from your norm, randomly even! (May I suggest some good ol’ Thompson sampling?)
Alright, let’s get into it!!
Things on My Mind
Have You Have Accepted ML Into Your Heart?
If you're reading this, it probably means you know me (Hi Mom! Yes, I saw you subscribe) or at the very least have some intersecting interests like machine learning & AI. So let's talk a little about that. (Sorry Mom, feel free to skip over this.)
LLMs in a New Space: Using Domain-Specific Embeddings Directly
I keep getting drawn back to this ‘Demystifying Embedding Spaces using Large Language Models’ paper since seeing it from a post by Catherine Breslin where the researchers had the goal of leveraging LLMs to make embeddings more interpretable. (
also has an excellent monthly Substack newsletter by the way: )The paper described a process where the base LLM tokens (think words) and a domain’s embeddings (for the paper, they used movie embeddings based on user ratings of the movies) to exist in a new shared embedding space. The researchers then trained a new LLM (via adapters) that can work in the new space. They call this new model an Embedding Language Model or ELM.
They were then able to go through some tasks in attempts to show how their new model (ELM) can operate in this new embedding space of tokens & domain embeddings. Below you can see a figure from the paper describing some tasks where the ELM can be prompted with both textual and domain embeddings and give outputs that would could be associated with the expected hypothetical embedding!
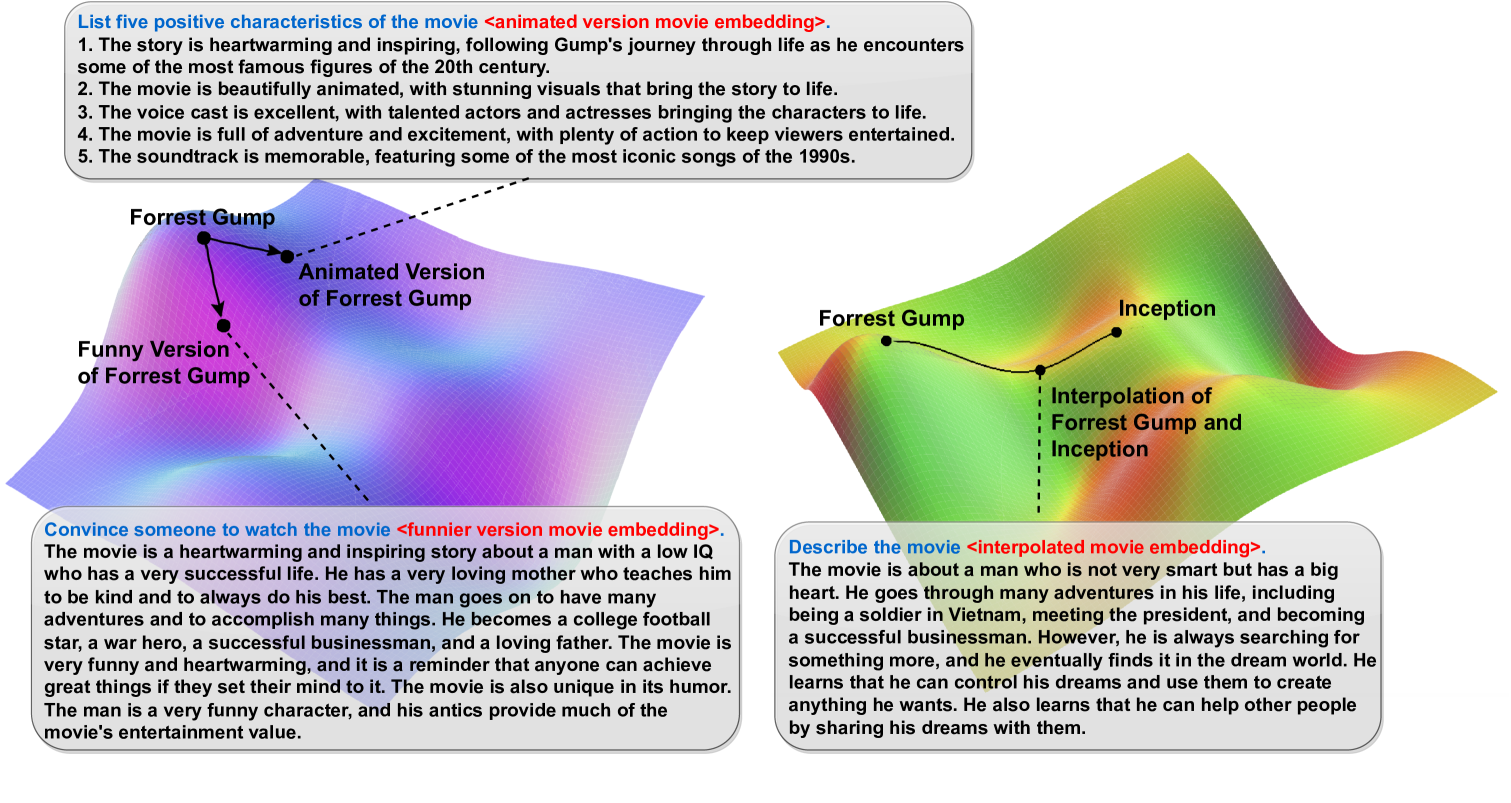
To break that down a bit, the new model was able to take an embedding representing a (non-existent) movie and produce output that seemed reasonable for that embedding. The model never saw this embedding during training, only some embeddings in the movie embedding space. So what we’re seeing is this ELM being able to directly use the pattern in embeddings and extrapolate.
I think this could be so great in being able to directly work in an embedding space. Embedding vectors are used everywhere in ML/AI. I’d be fascinated to see if you can leverage the pattern recognition of LLMs to work with embeddings more directly. If this method can be generalized, I can imagine using this like how RAG is used today but instead being able to use fewer tokens to reference external documents outside of the LLM.
I’ve been really wanting to try and reproduce this myself (at a small scale), but I kept getting pulled back with life (especially with being on & off sick this past month). I’m hoping I can implement a version of this one day soon! It’d be interesting to see if this methodology can extend to other embedding spaces, preferably with an open model that can be run locally. So when I finally get to this, I’ll be sure to share an update!
Lookout Transformers & Attention– Here Comes Linear Scaling LLMs
If you’ve had your ear to the ground, you might’ve already heard that something could be coming for the transformer architecture for LLMs.
Current LLMs are all pretty much based on the transformer architecture which came out from the now famous 2017 paper ‘Attention Is All You Need’. This use of the attention mechanism has allowed very robust & capable models that we now associate with ChatGPT, Gemini, and more.
However, there’s a bit of an issue that this architecture scales roughly quadratically which means to process 10x more tokens, you need roughly 10²=100 times more computing resources. With 100x more tokens, requirements become ~10,000 larger.
With the motivation to reduce the need for more compute, there have been some interesting proposals that would scale better such as the ‘Mamba’ architecture that uses state spaces (see the paper from the end of 2023). These techniques haven’t quite rivaled the state of the art that transformers provide. But the motivation is definitely there.
When Google publicly released their new set of Gemma open models in early April, their ‘RecurrentGemma’ model caught my eye almost immediately (paper). The idea was that it used the ‘Griffin’ architecture which leans on recurrent neural networks (RNNs) with local attention to reduce memory usage. This leads to higher throughput (how quickly the model can perform inference) especially with generating longer sequences.
The reason I perked up is not that this was a new technique, but the fact that Google (which for the record I work for) released an open model of this. To me that says a lot in that the Gemma team (and by extension Google) wants others in the ML/AI community to play around with something like RecurrentGemma. (By the way, you can check out the model on in Google DeepMind’s repo.)
Do I think this will be the methodology that will overthrow the ‘Attention is All You Need’ era of the transformers? I wouldn’t put a heavy bet on it. There are other techniques being tested & researched that also push in this direction away from quadratic scaling. But I do think this signals even more that the ML/AI space (specifically LLMs) is preparing to move away from Transformers which is in itself very exciting!
Fine, I’ll Read Some Fake Stories
I’ve really enjoyed reading. I personally don’t think of myself as a big ‘book reader’ but apparently others think I am. I guess the more than one picture of the stack of books I’ve shared is hard to argue against.


But one thing I tend to read is mostly non-fiction, especially technical stuff. (I do have quite an O’Reilly books collection.) I know part of the reason why is because I like to learn. (I know it’s cliché but it’s the truth!) But I think the other reason is I like ‘ideas’ over ‘individuals’.
I’ve noticed that when I do read made-up stories fiction, I tend not to remember the character names. One of my recent fiction reads was ‘This Is How You Lose the Time War’ and I’ve really loved reading that book! But even then, it’s not like a typical fiction read. I’ve heard it described as ‘poetry in prose’ and structured as letters being written back & forth between characters (an ‘epistolary novel’ if you want to be fancy).
So to cut to the chase, I generally don’t read fiction.
I’ve decided to read more fiction.
And here you go ‘*gasp* Wait, what?!’ Yes, I’ve decided this year that I’m going to make a conscious effort to read more fake stories, eh, I mean fiction.
I think doing something new and/or at a different degree is good for the soul. It might be an awful experience, but I think it helps your personal growth. Even if it is just confirming that you were right all along. (This leads well into the next section by the way.)
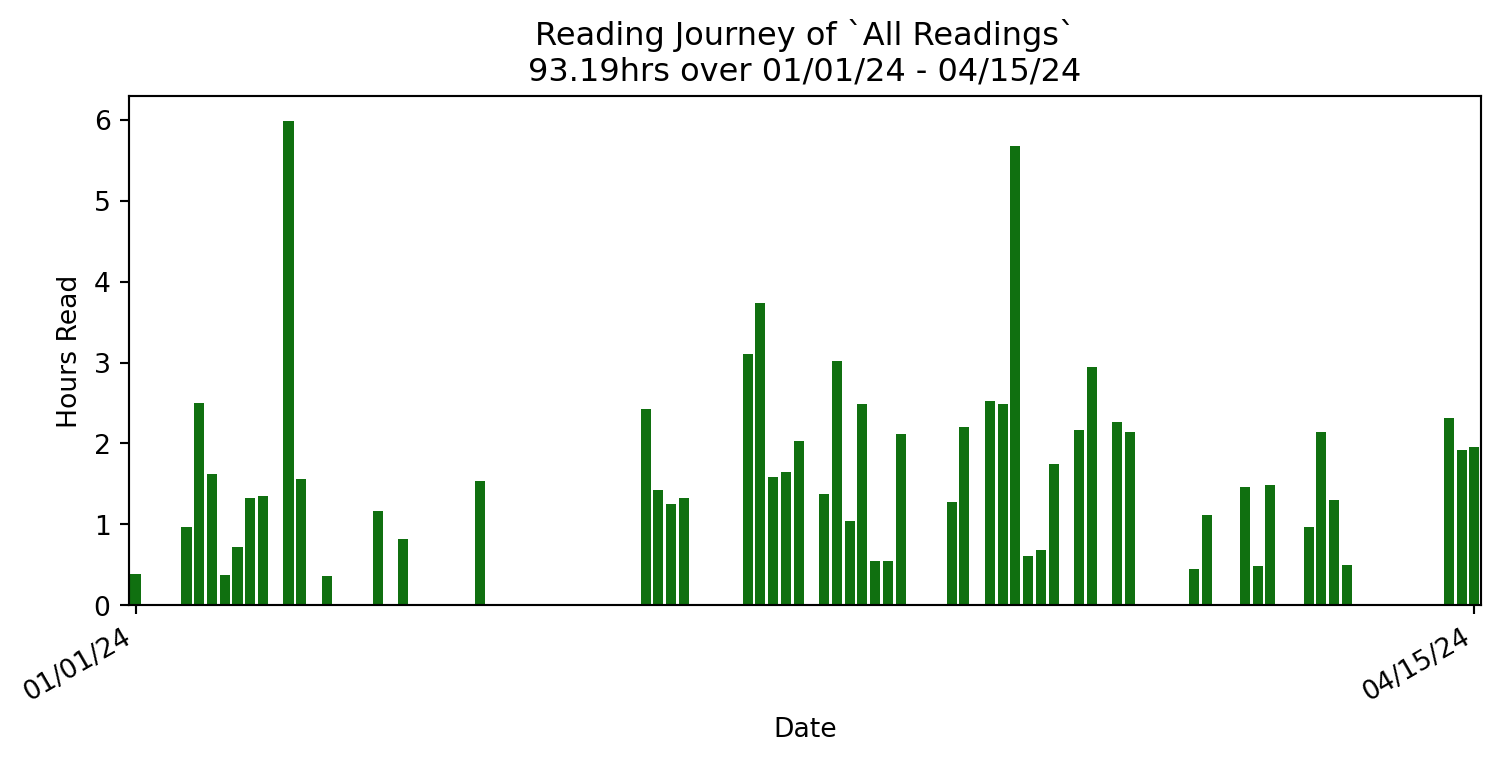
So if you have any recommendations definitely let me know! You can also follow along with what I read here: victorsothervector.com/books
Something New
Did you know we’re just over 100 days into 2024? The 100th day was in the second week of April. Doesn’t that feel wrong somehow? The world is just zipping by! But I think that makes this a perfect time to readjust & try something new.
New Years’ Resolutions Revisited
Do you remember your 2024 resolutions? Statistically, they’re not going well. But I think that’s okay!
I always felt the start of Lent (the day after Mardi Gras) was a good ‘2nd chance resolution’. It falls sometime in mid-February to early-March which is just about enough time to fail your resolution while still having enough motivation to start again.
The ‘3rd chance resolution’ date comes around Easter time. I think the 100th day into the year might actually be a better one though, since it’s got the nice round number going for it.
So we’re past 100 days, time to restart the resolution? I actually say let’s do something different. Let’s make some new, shorter resolutions.
I like this idea of ‘yearly themes’ over smaller ‘seasons’. Check out the video below that describes this concept:
Previous Season on Victor’s Life
Last ‘season’ for me was about all about focusing on getting back to a baseline. I felt I didn’t need to do something new but instead focus on creating a comfortable new ‘normal’.
This made sense to me since I was starting a position at Google in January where I felt I could grow & be challenged. I wanted time to get comfortable in my new role without adding anything too new or demanding.
I also wanted to get back to reading. I felt I took a ‘break’ last year as I searched for a new ML/AI-focused role where I read less than half the books I did in prior years. I realized that it was just too much of a cut back and needed to find a good ‘pace’ again. It seems that roughly a book or so per week seems right for me. (Follow along on with what I read on victorsothervector.com/books if you’re interested.)
I went back into being a bit more active on Threads as my social media go-to. I wanted to put my genuine self out there. And I’m glad I did! I’ve been having great conversations & discussions, especially centering around the current ML/AI space. I also found a new friend and been a guest on their podcast focusing on ‘non-technical’ folks wanting to learn more about this whole ‘AI’ thing. (Shoutout to
running the project– podcast & their newsletter: )It’s been eventful and fulfilling season (even if various colds & such sprinkled throughout it)!
New Season for Victor: Make It New & Better
My new ‘season’ started about the start of April and this time I’m focused on improving past my ‘baseline’ and trying new things!
I’ve already talked about how I’m reading more fiction. I’m really turning up the dial with hopes that it also won’t discourage me from keep reading. I finally read ‘Turtles All the Way Down’ this month and it was quick read that had such an interesting way of depicting someone with OCD & anxiety’s internal monologue. (I love when the written form is played around with beyond the words said!) I’ve also started reading ‘Dune’ recently & it’s been enjoyable!
I’ve started being more conscious about making time to work out and just be outside. Especially with the weather being nice, it’s been so refreshing
I’ve also been thinking about trying something new, like learning a language or revisiting my ASL fluency. I’m even considering trying to learn an instrument! But we’ll see if that happens!
A Central Hub: My Website
I tend to have a ‘dig your own well’ attitude (even when I don’t have the follow through). I always felt a little uneasy relying too heavily on something where I don’t have much control. Even if the solution isn’t as polished or even as functional, sometimes just knowing that I have the freedom to pack my things up and move it to somewhere else.
This brings me to where I’ve been pointing people to: my GitHub profile. I’ve been using GitHub for over a decade (damn I’m getting old) starting back in my university days. Although I don’t have control over it directly, with it’s association with open source projects, it felt like the right place to use as my central hub to different places to find my stuff (YouTube, social media, etc.) But I also knew GitHub was another place I didn’t control.
I feel a place that linked all my profiles was important to have so people can find things I was doing. But also, another reason was that I didn’t want to worry about updating multiple places when I started/stopped using a platforms. (For example, I’ve stopped using Twitter & have been decently engaged on Threads @victorsothervector)
All of these considerations led me to finally put a real effort in making a site that I can point people to: VictorsOtherVector.com
Find me at VictorsOtherVector.com 👈🏼
I also plan to expand out my site with more pages and things I want to share. I’ve already experimented with my ‘reading journey’ at victorsothervector.com/books/ (mentioned earlier) but I have plans to write blog posts about ML & other musings. I’ve even played around with the idea making some kind of ML/AI course.
The point is this is much more flexible in what I can do! The newsletter (this guy that you’re reading) will focus more with updates and point to things I want to share. That way I can point
And most importantly to me, I can pack up my stuff, move somewhere new, and dig my own well whenever I want.
The Future of This Newsletter
So this newsletter, if you allow me to be blunt, is too long! At over 2,500 words, I know it’s a lot. That’s part of the reason why I suggested skimming & skipping around to what sounds interesting to you.
I actually knew that this first post was going to be long because this is partially an explanation of my motivation for this newsletter. But don’t expect future newsletters to be like this.
This newsletter is too long! That’s alright, future newsletters will be shorter.
Instead, the newsletter will focus on pointing to things I find interesting. Maybe something I created myself (a blog post, a video, etc.) or maybe something someone else made that I’ve come across. This newsletter is intended to be a jumping off point to something you’re interested in.
Also, this newsletter is not meant to be too frequent. I’m nearly certain if I tried to do that, I'd fail in ever sharing anything. Plus, did you really need another thing that piles into your inbox every week for you to ignore?
My goal here is to make this analogous to a random plate of treats you can take a bite of, but never obligated to digest in full. My hope is parts of this newsletter interests you and find something joyful from it all!
🍭🍬🍭
you're such a great communicator